


Monitoring your servers is a natural part of a DBA's responsibilities and essential for delivering reliable and stable services. But are all SQL monitoring tools created equal?
This article concerns the why, what, and how to monitor SQL servers. With this knowledge in hand, you are better equipped to decide what you need from a monitoring tool and how to benefit from it.
The first thing you want to do as a DBA is to see the status of the database instances you manage – and that’s where we start with SQL monitoring. With only a handful of instances, you may be able to do it by hand, but once the numbers start increasing, you will need some kind of tool or solution to help you. And that’s where you face the first question – what monitoring tool should I use?
There are many SQL monitoring solutions to choose from, or you can roll your own – so let´s talk about what is important and why when it comes to monitoring SQL servers.
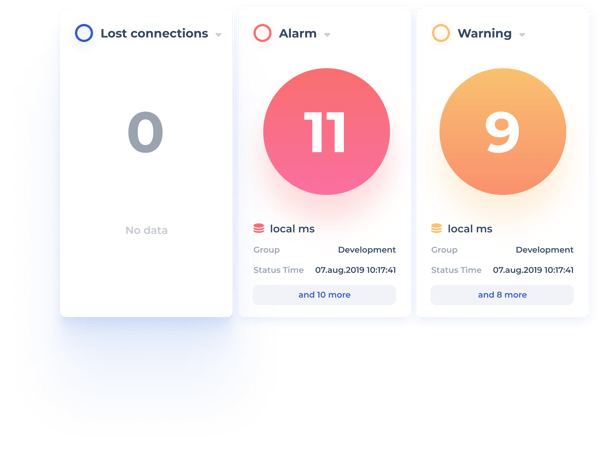
Monitoring solutions can collect a lot of data. More data leaves you overwhelmed, and looking for that needle of useful information in the haystack of raw data can be frustrating. Too little information can lead to an inability to locate issues or reach incorrect conclusions, which can be very costly.
If you collect too much data, you will run into two other problems as well:
Automation can scan through all that data and notify you only when something is out of the normal and needs your attention.
You will then need to turn the raw data into useful information that gives you insight into what's going on and what you can do about it.
What's important is how you present the data and how you can turn the data into useful, actionable information.
Good monitoring tools should be able to automate most, if not all, of this for you.

Monitoring can be a simple task or a complex and exhaustive process for full control over larger complex estates depending on your ambition and needs.
What you decide to implement will depend on the organization's requirements, your budget, and your skills.
If you do decide to invest in a 3rd party solution, there are many things to consider that we have highlighted here. Since you will usually live for a long time with an investment in a monitoring solution, you need to spend some time deciding what you need now ( and in the future as things grow and expand) before you jump in.
The cost of a monitoring solution can be considerable, but so can the benefits.
Look for capabilities for preventive operations, performance management, resource utilization, and, most importantly, much-improved productivity and DBA satisfaction.
© 2024 dbWatch AS





